
事务的解决方案
一、本地事务与分布式事务
1、事务
数据库事务(简称:事务,Transaction)是指数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
事务拥有以下四个特性,习惯上被称为ACID特性:
原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态是指数据库中的数据应满足完整性约束。除此之外,一致性还有另外一层语义,就是事务的中间状态不能被观察到(这层语义也有说应该属于原子性)。
隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行,如同只有这一个操作在被数据库所执行一样。
持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。在事务结束时,此操作将不可逆转。
2、本地事务
起初,事务仅限于对单一数据库资源的访问控制,架构服务化以后,事务的概念延伸到了服务中。倘若将一个单一的服务操作作为一个事务,那么整个服务操作只能涉及一个单一的数据库资源,这类基于单个服务单一数据库资源访问的事务,被称为本地事务(Local Transaction)。
3、分布式事务
分布式事务指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上,且属于不同的应用,分布式事务需要保证这些操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
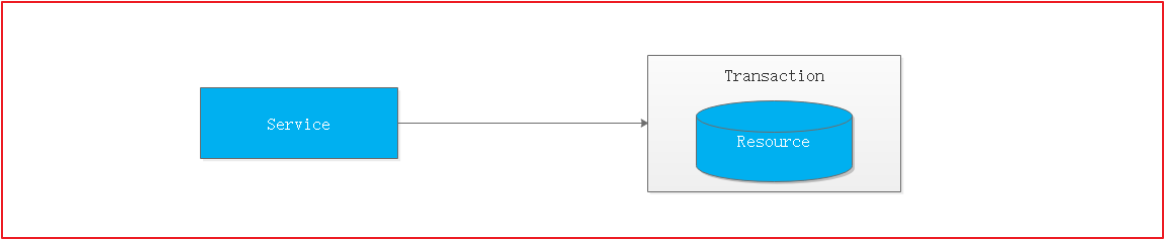
最早的分布式事务应用架构很简单,不涉及服务间的访问调用,仅仅是服务内操作涉及到对多个数据库资源的访问。
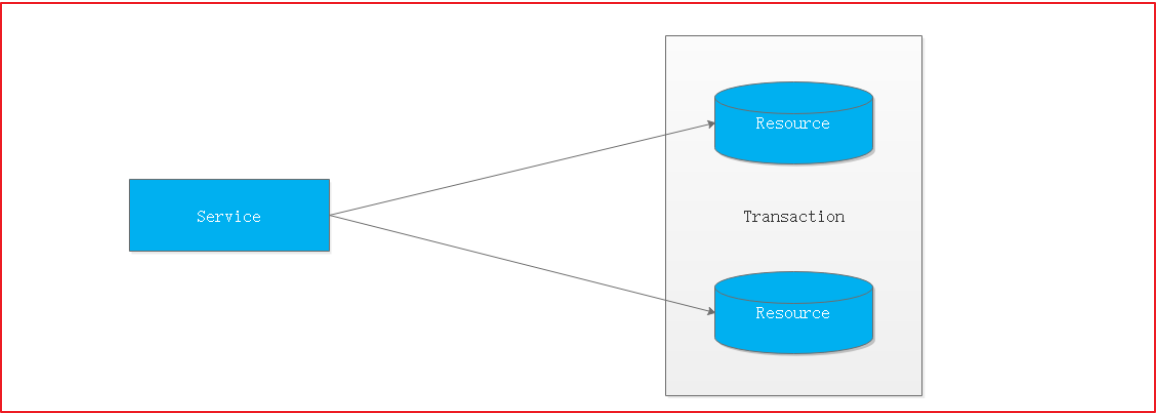
当一个服务操作访问不同的数据库资源,又希望对它们的访问具有事务特性时,就需要采用分布式事务来协调所有的事务参与者。
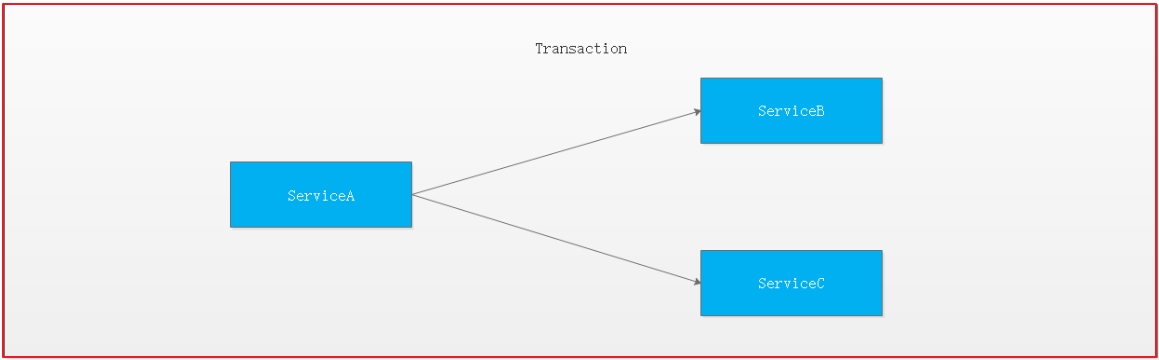
对于上面介绍的分布式事务应用架构,尽管一个服务操作会访问多个数据库资源,但是毕竟整个事务还是控制在单一服务的内部。如果一个服务操作需要调用另外一个服务,这时的事务就需要跨越多个服务了。在这种情况下,起始于某个服务的事务在调用另外一个服务的时候,需要以某种机制流转到另外一个服务,从而使被调用的服务访问的资源也自动加入到该事务当中来。下图反映了这样一个跨越多个服务的分布式事务:
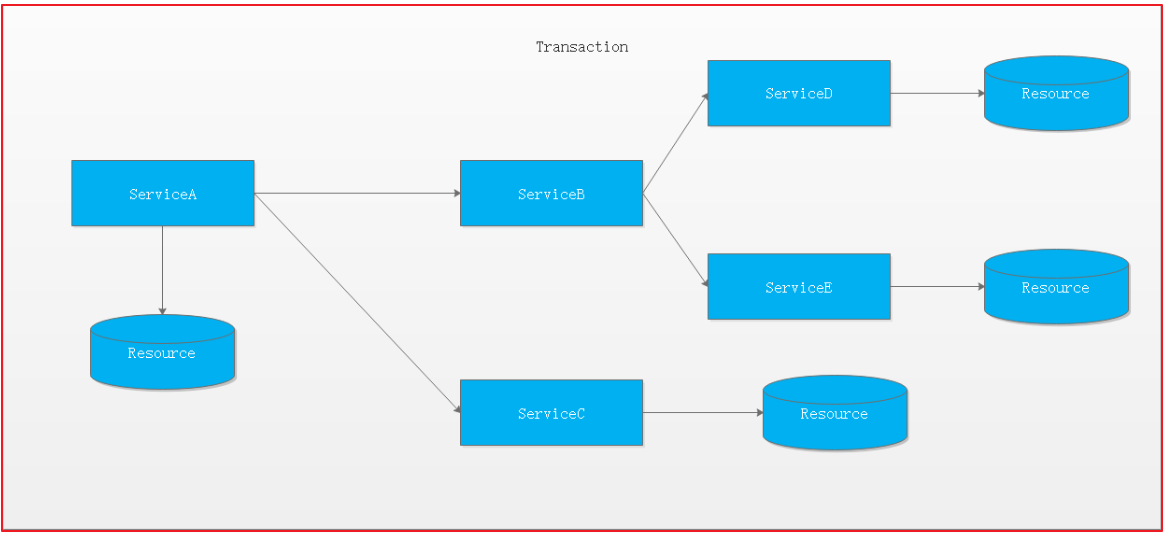
如果将上面这两种场景(一个服务可以调用多个数据库资源,也可以调用其他服务)结合在一起,对此进行延伸,整个分布式事务的参与者将会组成如下图所示的树形拓扑结构。在一个跨服务的分布式事务中,事务的发起者和提交均系同一个,它可以是整个调用的客户端,也可以是客户端最先调用的那个服务。
较之基于单一数据库资源访问的本地事务,分布式事务的应用架构更为复杂。在不同的分布式应用架构下,实现一个分布式事务要考虑的问题并不完全一样,比如对多资源的协调、事务的跨服务传播等,实现机制也是复杂多变。
二、分布式事务解决方案
1、基于XA协议的两阶段提交
首先我们来简要看下分布式事务处理的XA规范 :
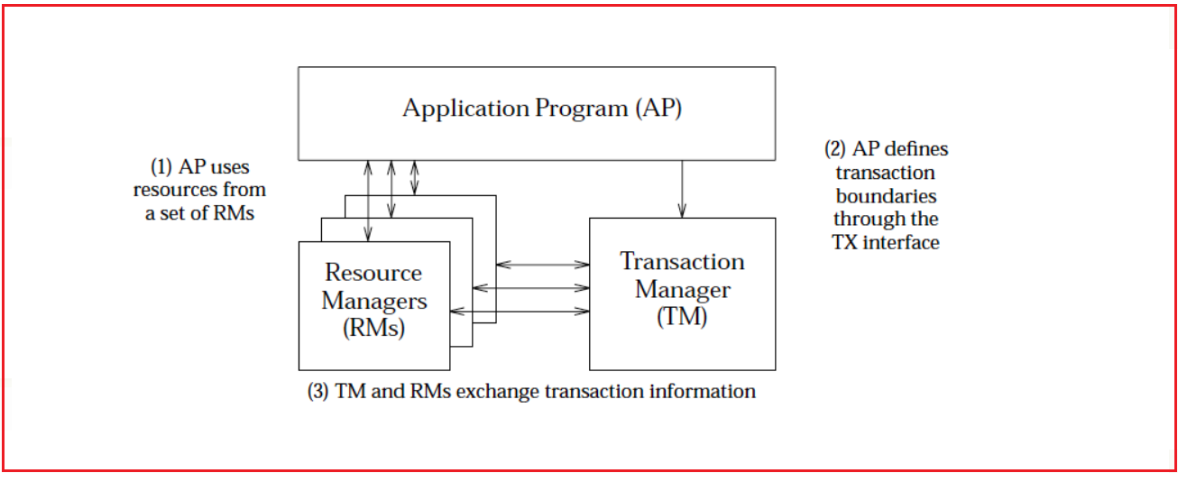
可知XA规范中分布式事务有AP,RM,TM组成:
其中应用程序(Application Program ,简称AP): AP定义事务边界(定义事务开始和结束)并访问事务边界内的资源。
资源管理器(Resource Manager,简称RM): Rm管理计算机共享的资源,许多软件都可以去访问这些资源,资源包含比如数据库、文件系统、打印机服务器等。
事务管理器(Transaction Manager ,简称TM): 负责管理全局事务,分配事务唯一标识,监控事务的执行进度,并负责事务的提交、回滚、失败恢复等。
二阶段协议:
第一阶段TM要求所有的RM准备提交对应的事务分支,询问RM是否有能力保证成功的提交事务分支,RM根据自己的情况,如果判断自己进行的工作可以被提交,那就就对工作内容进行持久化,并给TM回执OK;否则给TM的回执NO。RM在发送了否定答复并回滚了已经的工作后,就可以丢弃这个事务分支信息了。
第二阶段TM根据阶段1各个RM prepare的结果,决定是提交还是回滚事务。如果所有的RM都prepare成功,那么TM通知所有的RM进行提交;如果有RM prepare回执NO的话,则TM通知所有RM回滚自己的事务分支。
也就是TM与RM之间是通过两阶段提交协议进行交互的.
优点: 尽量保证了数据的强一致,适合对数据强一致要求很高的关键领域。(其实也不能100%保证强一致)
缺点: 实现复杂,牺牲了可用性,对性能影响较大,不适合高并发高性能场景。
2、TCC补偿机制
TCC 其实就是采用的补偿机制,其核心思想是:针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。它分为三个阶段:
- Try 阶段主要是对业务系统做检测及资源预留
- Confirm 阶段主要是对业务系统做确认提交,Try阶段执行成功并开始执行 Confirm阶段时,默认 Confirm阶段是不会出错的。即:只要Try成功,Confirm一定成功。
- Cancel 阶段主要是在业务执行错误,需要回滚的状态下执行的业务取消,预留资源释放。
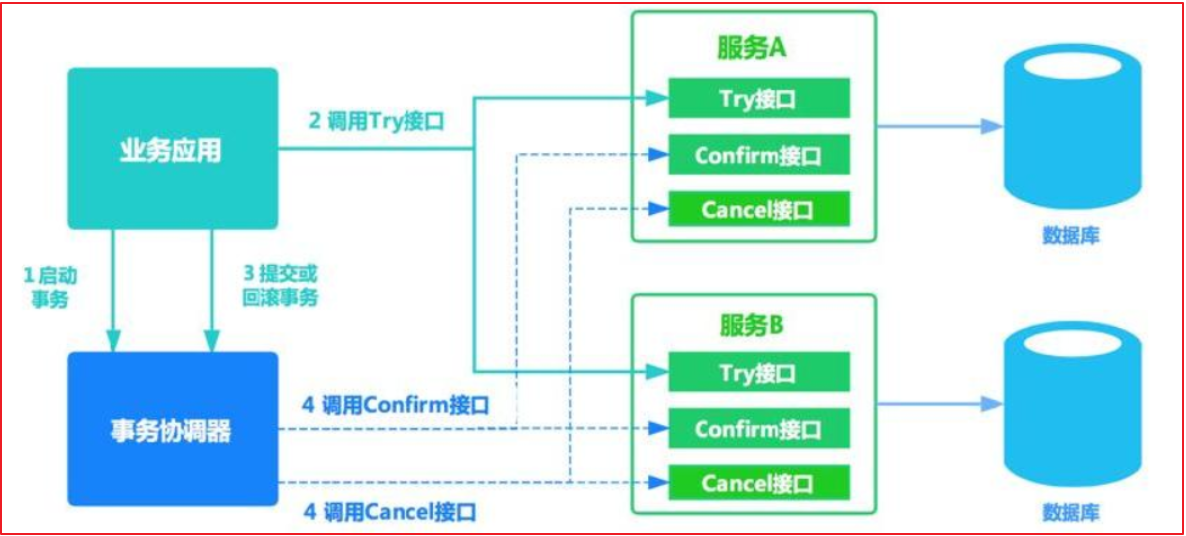
例如: A要向 B 转账,思路大概是:
我们有一个本地方法,里面依次调用
-
首先在 Try 阶段,要先调用远程接口把 B和 A的钱给冻结起来。
-
在 Confirm 阶段,执行远程调用的转账的操作,转账成功进行解冻。
-
如果第2步执行成功,那么转账成功,如果第二步执行失败,则调用远程冻结接口对应的解冻方法 (Cancel)。
优点: 相比两阶段提交,可用性比较强
缺点: 数据的一致性要差一些。TCC属于应用层的一种补偿方式,所以需要程序员在实现的时候多写很多补偿的代码,在一些场景中,一些业务流程可能用TCC不太好定义及处理。
3、MQ消息最终一致性
消息最终一致性其核心思想是将分布式事务拆分成本地事务进行处理,这种思路是来源于ebay。我们可以从下面的流程图中看出其中的一些细节:
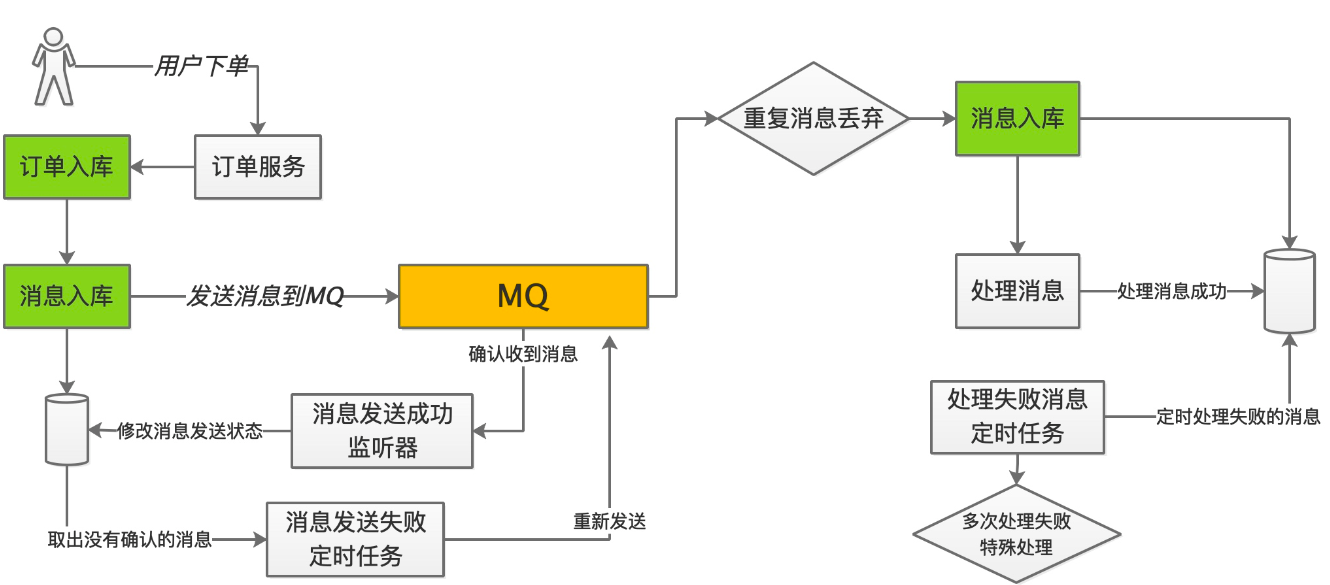
生产者的逻辑
1、订单入库
2、消息记录入库
3、发送消息(采用确认模式)
4、mq收到消息之后给生产端一个确认消息
5、生产端监听这个确认消息
6、根据监听结果操作消息表的状态
7、定时任务定时去操作消息状态为1未发送的记录,就是那些没有监听到结果的记录进行重新发送
消费者的逻辑
1、将收到消息的消息入库
2、处理消息失败消息记录的状态就为未处理
3、处理消息成功修改消息记录的状态为处理成功
4、收到相同的消息id的消息直接丢弃
5、定时任务去操作那些未处理,并且已经经过一段时间的消息
6、针对那些一直处理失败的,且很长一段时间都没办法处理成功的消息交由人工或者其他途径处理
优点: 一种非常经典的实现,避免了分布式事务,实现了最终一致性。
缺点: 消息表会耦合到业务系统中,如果没有封装好的解决方案,会有很多杂活需要处理。
