
多级缓存
一、多级缓存解决方案
当我们遇到到的并发大的问题,一般而言,解决查询并发大的问题,常见的手段是为查询接口增加缓存,从而可以减轻持久层的压力。
按照我们以往的经验,在查询接口中增加Redis缓存即可,将查询的结果数据存储到Redis中,执行查询时首先从Redis中命中,如果命中直接返回即可,没有命中查询MongoDB,将解决写入到Redis中。
这样就解决问题了吗?其实并不是,试想一下,如果Redis宕机了或者是Redis中的数据大范围的失效,这样大量的并发压力就会进入持久层,会对持久层有较大的影响,甚至可能直接崩溃。
如何解决该问题呢,可以通过多级缓存的解决方案来进行解决。
1、什么是多级缓存
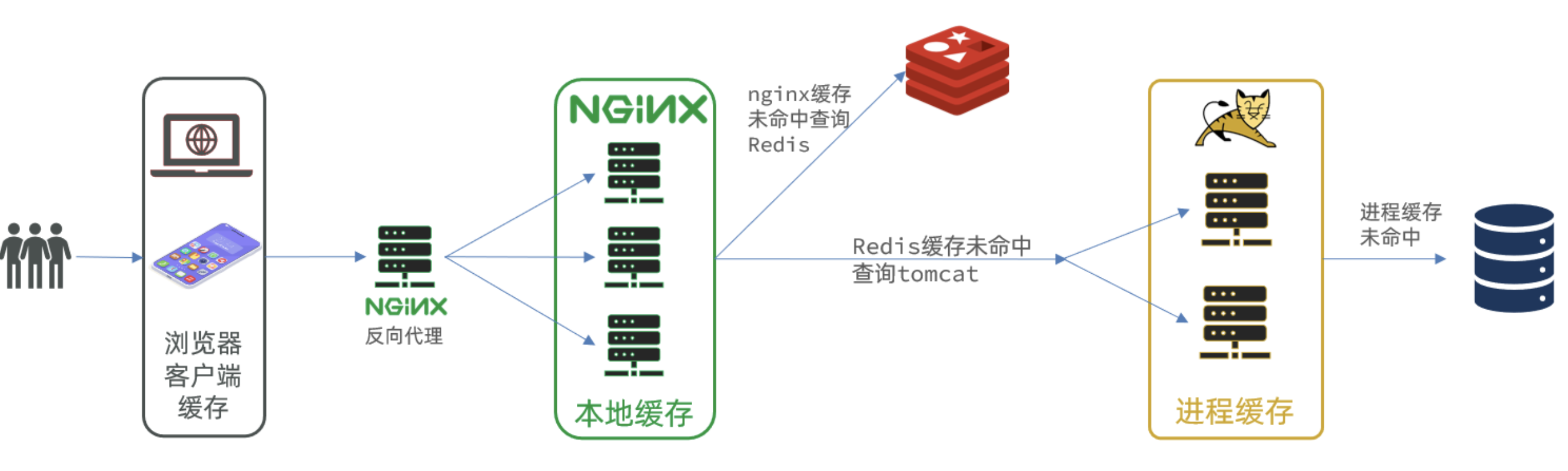
由上图可以看出,在用户的一次请求中,可以设置多个缓存以提升查询的性能,能够快速响应。
- 浏览器的本地缓存
- 使用Nginx作为反向代理的架构时,可以启用Nginx的本地缓存,对于代理数据进行缓存
- 如果Nginx的本地缓存未命中,可以在Nginx中编写Lua脚本从Redis中命中数据
- 如果Redis依然没有命中的话,请求就会进入到Tomcat,也就是执行我们写的程序,在程序中可以设置进程级的缓存,如果命中直接返回即可。
- 如果进程级的缓存依然没有命中的话,请求才会进入到持久层查询数据。
以上就是多级缓存的基本的设计思路,其核心思想就是让每一个请求节点尽可能的进行缓存操作。
二、Caffeine快速入门
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库,也就是可以通过Caffeine实现进程级的缓存。Spring内部的缓存使用的就是Caffeine。
官网地址:https://github.com/ben-manes/caffeine
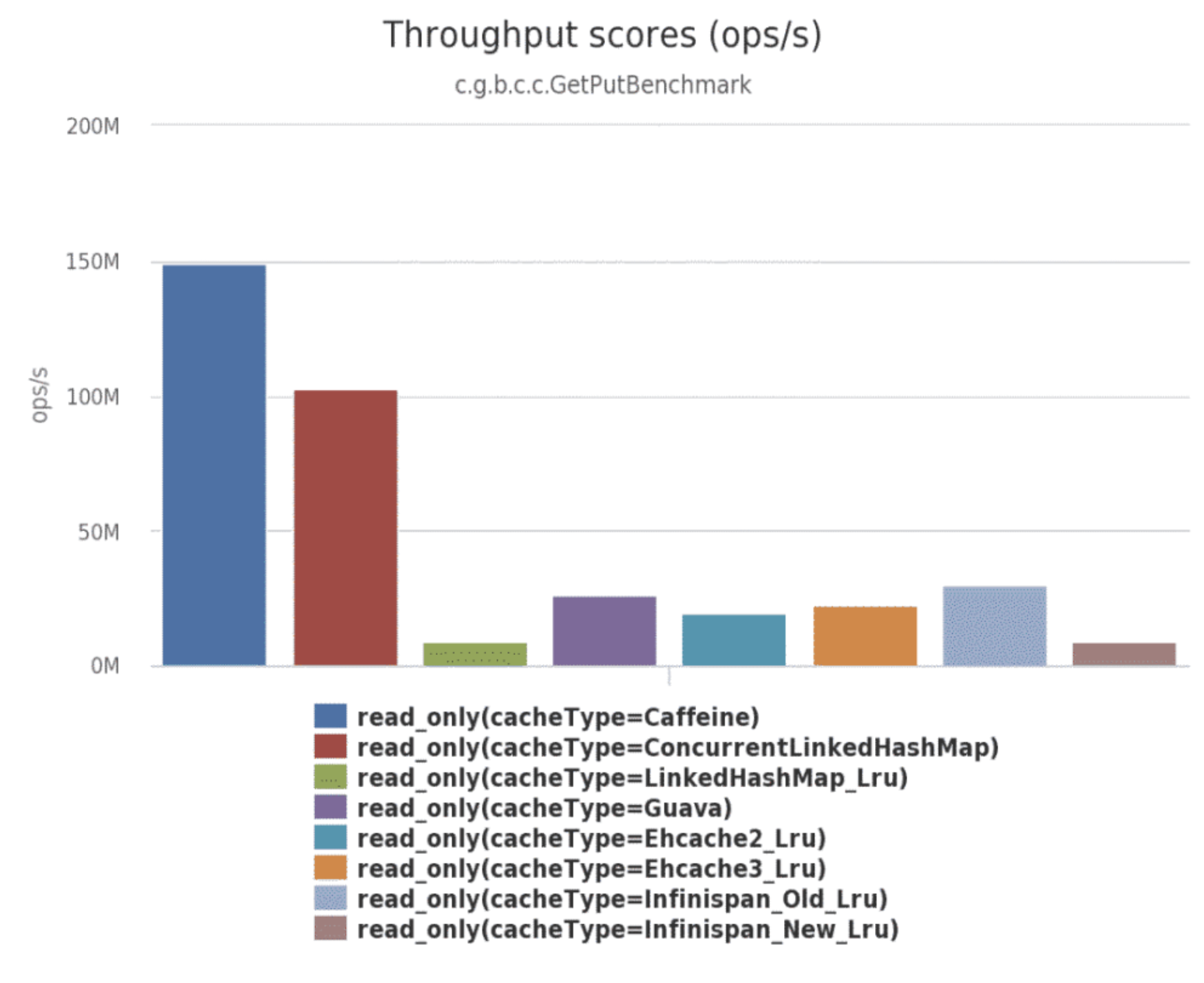
Caffeine的性能非常强悍,下图是官方给出的性能对比:
1、使用
- 引入依赖
<!--jvm进程缓存-->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
- 测试使用
public class CaffeineTest {
@Test
public void testCaffeine() {
// 创建缓存对象
Cache<String, Object> cache = Caffeine.newBuilder()
.initialCapacity(10) //缓存初始容量
.maximumSize(100) //缓存最大容量
.build();
//将数据存储缓存中
cache.put("key1", 123);
// 从缓存中命中数据
// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是在未命中时执行
// 优先根据key查询进程缓存,如果未命中,则执行参数二的Lambda表达式,执行完成后会将结果写入到缓存中
Object value1 = cache.get("key1", key -> 456);
System.out.println(value1); //123
Object value2 = cache.get("key2", key -> 456);
System.out.println(value2); //456
}
}
2、驱逐策略
Caffeine既然是缓存的一种,肯定需要有缓存的清除策略,不然的话内存总会有耗尽的时候。
Caffeine提供了三种缓存驱逐策略:
- 基于容量:设置缓存的数量上限
@Test
public void test2() throws InterruptedException {
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1,当缓存超出这个容量的时候,会使用Window TinyLfu策略来删除缓存。
.build();
new Thread(()->{
cache.put("key1","123");
System.out.println("当前key1的值: " + cache.get("key1", k->"没有值"));
}).start();
Thread.sleep(1000);
new Thread(()->{
cache.put("key2","456");
System.out.println("当前key2的值: " + cache.get("key2", k->"没有值"));
}).start();
Thread.sleep(1000);
new Thread(()->{
System.out.println(cache);
}).start();
}
- 基于时间:设置缓存的有效时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();
- 基于引用:设置缓存为软引用或弱引用,利用GC来回收缓存数据。性能较差,不建议使用。
注意:在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
三、实战案例
1、一级缓存
- 下面我们通过增加Caffeine实现一级缓存
1.1 Caffeine配置
/**
* Caffeine缓存配置
*/
@Configuration
public class CaffeineConfig {
@Value("${caffeine.init}")
private Integer init;
@Value("${caffeine.max}")
private Integer max;
@Bean
public Cache<String, TransportInfoDTO> transportInfoCache() {
return Caffeine.newBuilder()
.initialCapacity(init)
.maximumSize(max).build();
}
}
- 注意:配置类中读取了配置文件,需要在配置文件中进行配置
caffeine.init = 100
caffeine.max = 10000
1.2 实现缓存逻辑
@ApiImplicitParams({
@ApiImplicitParam(name = "transportOrderId", value = "运单id")
})
@GetMapping("/{transportOrderId}")
public TransportInfoDTO queryByTransportOrderId(@PathVariable("transportOrderId") String transportOrderId) {
TransportInfoDTO transportInfoDTO = this.transportInfoCache.get(transportOrderId, s -> {
TransportInfoEntity transportInfoEntity = this.transportInfoService.queryByTransportOrderId(transportOrderId);
return BeanUtil.toBean(transportInfoEntity, TransportInfoDTO.class);
});
if (ObjectUtil.isNotEmpty(transportInfoDTO)) {
return transportInfoDTO;
}
throw new SLException(ExceptionEnum.NOT_FOUND);
}
2、二级缓存
二级缓存通过Redis的存储实现,这里我们使用Spring Cache进行缓存数据的存储和读取。
2.1 Reids配置
Spring Cache默认是采用jdk的对象序列化方式,这种方式比较占用空间而且性能差,所以往往会将值以json的方式存储,此时就需要对RedisCacheManager进行自定义的配置。
/**
* Redis相关的配置
*/
@Configuration
public class RedisConfig {
/**
* 存储的默认有效期时间,单位:小时
*/
@Value("${redis.ttl:1}")
private Integer redisTtl;
@Bean
public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
// 默认配置
RedisCacheConfiguration defaultCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
// 设置key的序列化方式为字符串
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))
// 设置value的序列化方式为json格式
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()))
.disableCachingNullValues() // 不缓存null
.entryTtl(Duration.ofHours(redisTtl)); // 默认缓存数据保存1小时
// 构redis缓存管理器
RedisCacheManager redisCacheManager = RedisCacheManager.RedisCacheManagerBuilder
.fromConnectionFactory(redisTemplate.getConnectionFactory())
.cacheDefaults(defaultCacheConfiguration)
.transactionAware() // 只在事务成功提交后才会进行缓存的put/evict操作
.build();
return redisCacheManager;
}
}
2.2 添加缓存注解
SpringCache更详细的使用请参考 《SpringCache基础使用》
@Override
@CachePut(value = "transport-info", key = "#p0") //更新缓存数据
public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {
//省略代码
}
@Override
@Cacheable(value = "transport-info", key = "#p0") //新增缓存数据
public TransportInfoEntity queryByTransportOrderId(String transportOrderId) {
//省略代码
}
2.3 一级缓存更新问题
注意:在更新Reids数据后需要同步更新Caffeine中的数据
四、分布式场景下产生的问题
1、问题分析
通过前面的解决,貌似可以完成一级、二级缓存中数据的同步,如果在单节点项目中是没有问题的,但是,在分布式场景下是有问题的,看下图:
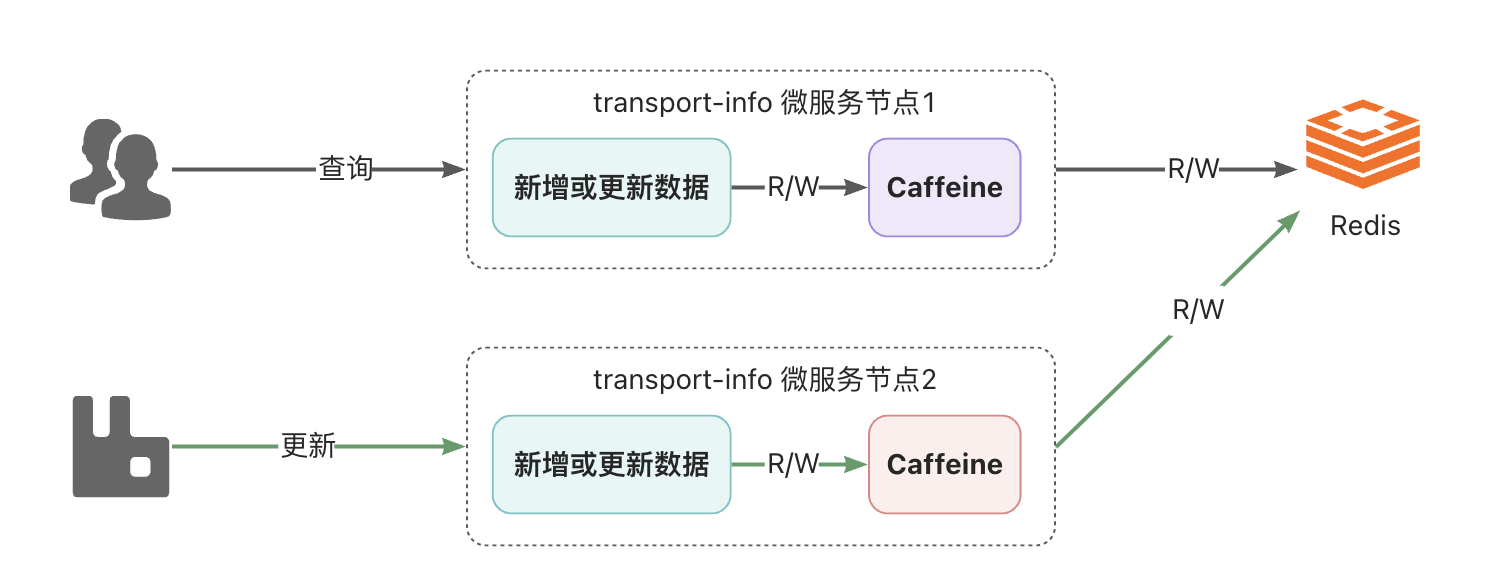
说明:
- 部署了2个transport-info微服务节点,每个微服务都有自己进程级的一级缓存,都共享同一个Redis作为二级缓存
- 假设,所有节点的一级和二级缓存都是空的,此时,用户通过节点1查询运单物流信息,在完成后,节点1的caffeine和Redis中都会有数据
- 接着,系统通过节点2更新了物流数据,此时节点2中的caffeine和Redis都是更新后的数据
- 用户还是进行查询动作,依然是通过节点1查询,此时查询到的将是旧的数据,也就是出现了一级缓存与二级缓存之间的数据不一致的问题
2、解决方案
如何解决该问题呢?可以通过消息的方式解决,就是任意一个节点数据更新了数据,发个消息出来,通知其他节点,其他节点接收到消息后,将自己caffeine中相应的数据删除即可。
关于消息的实现,可以采用RabbitMQ,也可以采用Redis的消息订阅发布来实现,在这里为了应用技术的多样化,所以采用Redis的订阅发布来实现。
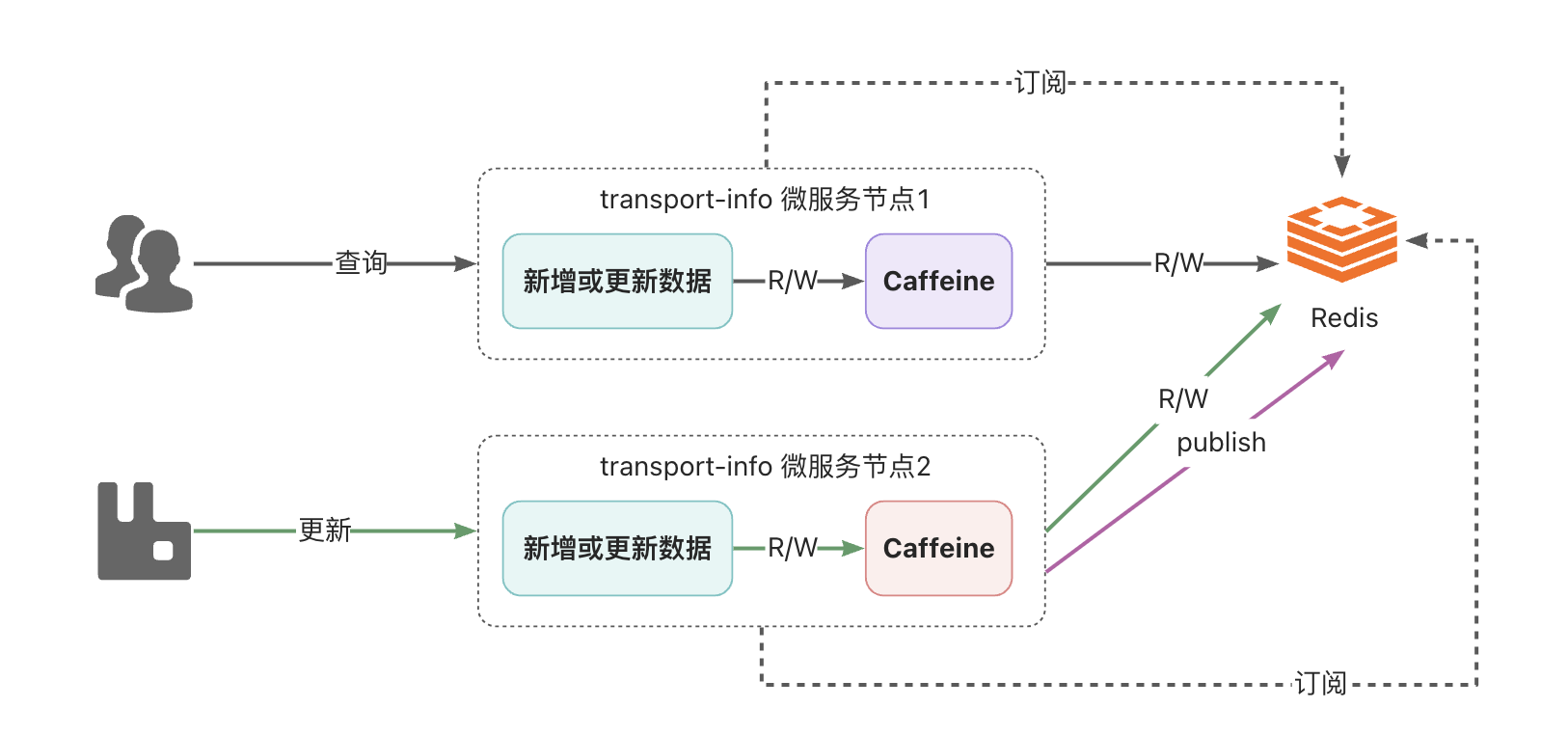
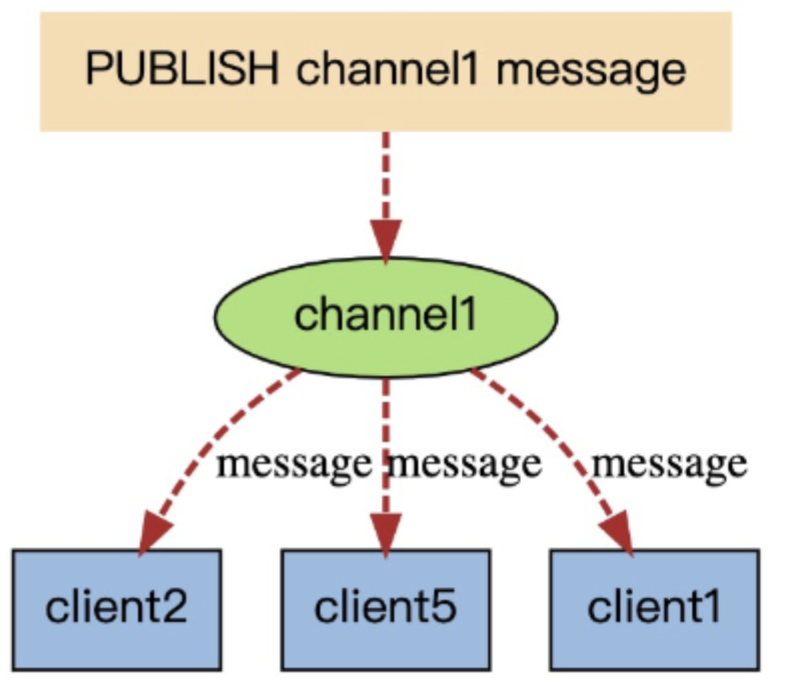
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
当有新消息通过 publish 命令发送给频道 channel1 时, 这个消息就会被发送给订阅它的三个客户端。
Redis的订阅发布功能与传统的消息中间件(如:RabbitMQ)相比,相对轻量一些,针对数据准确和安全性要求没有那么高的场景可以直接使用。
- 在RedisConfig配置类中新增配置信息
public static final String CHANNEL_TOPIC = "leaf-transport-info-caffeine";
/**
* 配置订阅,用于解决Caffeine一致性的问题
*
* @param connectionFactory 链接工厂
* @param listenerAdapter 消息监听器
* @return 消息监听容器
*/
@Bean
public RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory,
MessageListenerAdapter listenerAdapter) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.addMessageListener(listenerAdapter, new ChannelTopic(CHANNEL_TOPIC));
return container;
}
- 编写RedisMessageListener用于监听消息,删除caffeine中的数据。
/**
* redis消息监听,解决Caffeine一致性的问题
*/
@Component
public class RedisMessageListener extends MessageListenerAdapter {
@Resource
private Cache<String, TransportInfoDTO> transportInfoCache;
@Override
public void onMessage(Message message, byte[] pattern) {
//获取到消息中的运单id
String transportOrderId = Convert.toStr(message);
//将本jvm中的缓存删除掉
this.transportInfoCache.invalidate(transportOrderId);
}
}
- 更新数据后发送消息
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
@CachePut(value = "transport-info", key = "#p0")
public TransportInfoEntity saveOrUpdate(String transportOrderId, TransportInfoDetail infoDetail) {
//省略代码
//清除缓存中的数据
// this.transportInfoCache.invalidate(transportOrderId);
//发布订阅消息到redis
this.stringRedisTemplate.convertAndSend(RedisConfig.CHANNEL_TOPIC, transportOrderId);
//保存/更新到MongoDB
return this.mongoTemplate.save(transportInfoEntity);
}
